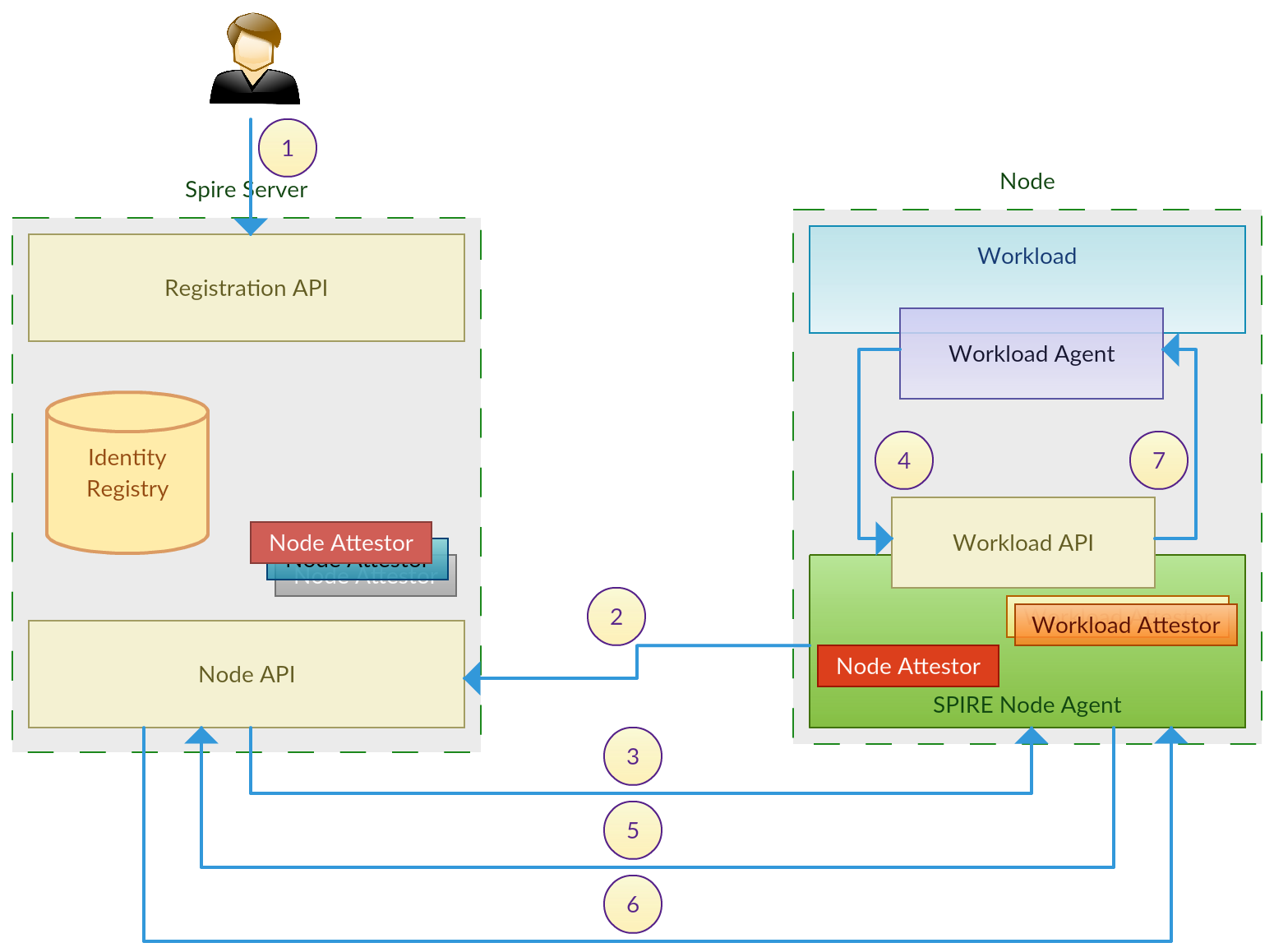
OPA for HTTP Authorization
Open Policy Agent[1] is a promising, light weight and very generic policy engine to govern authorization is any type of domain. I found this comparion[2] very attractive in evaluating OPA for a project I am currently working on, where they demonstrate how OPA can cater same functionality defined in RBAC, RBAC with Seperation of Duty, ABAC and XACML. Here are the steps to a brief demonstration of OPA used for HTTP API authorization based on the sample [3], taking it another level up. Running OPA Server First we need to download OPA from [4], based on the operating system we are running on. For linux, curl -L -o opa https://github.com/open-policy-agent/opa/releases/download/v0.10.3/opa_linux_amd64 Make it executable, chmod 755 ./opa Once done, we can start OPA policy engine as a server. ./opa run --server Define Data and Rules Next we need to load data and authorization rules to the server, so it can make decisions. OPA defines these in f...